自然语言处理范式总结
范式就是规范的意思,在自然语言处理领域目前总共可分为四个里程碑及四个范式,分别为:

- 第一个范式为1990年以前的处理方法,基本为字典/词典辅以规则
- 第二个范式主要是2000-2012年的统计机器学习模型
- 第三个范式则是以深度学习为代表的模型,端到端的神经网络模型
- 第四个范式是以预训练语言模型加微调为主,再进行模型压缩
详尽的预处理模型关系图
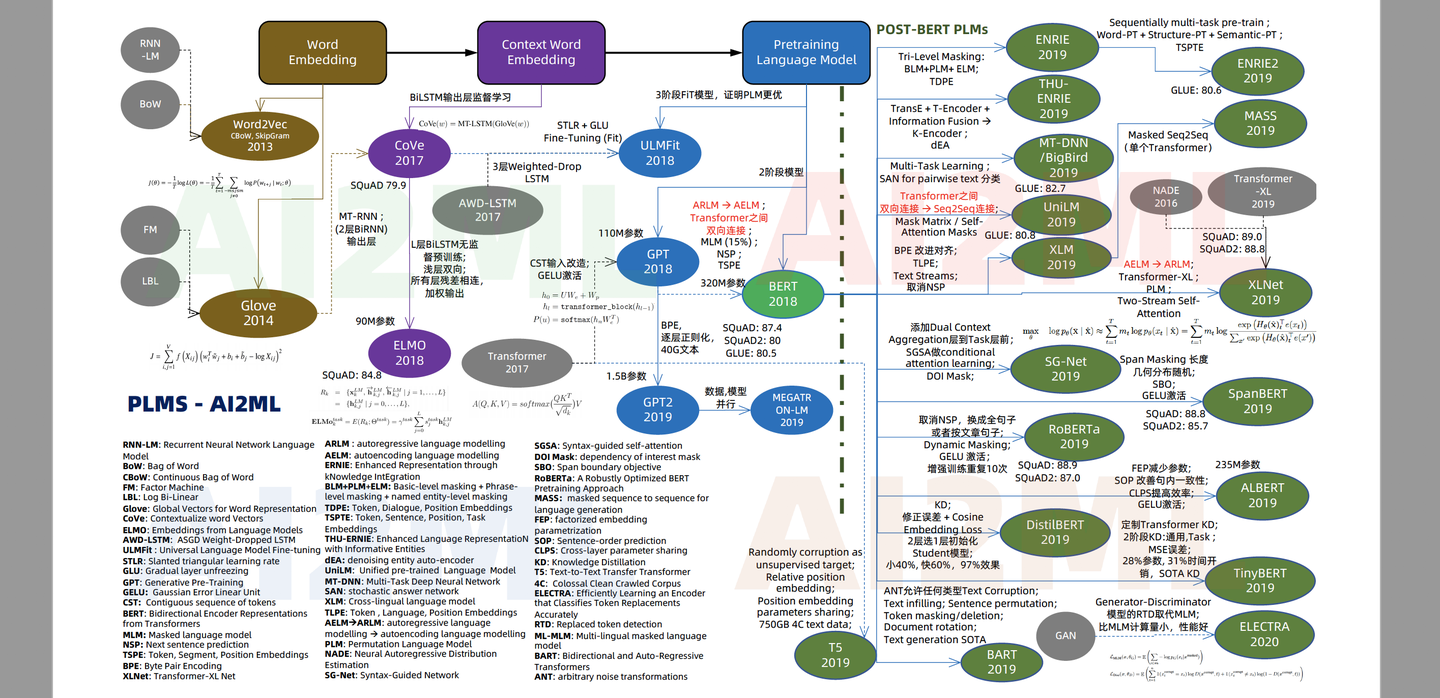
- 预训练语言模型
模型可以通过监督学习方法获得,这是最常规的统计学习思路
今年来涌现的预训练语言模型则可利用三种不同类型的数据学习得到模型:
- 生文本:通过自监督学习(self-supervised learning)得到预训练模型
- 辅助任务标注数据:通过预训练(pre-training)得到预训练模型
- 标注数据:通过精调(fine-tuning)得到预训练模型

词向量时代
预训练语言模型时代
预处理范式时间轴

各种预处理语言模型发展关系图
